Understanding how Transformers solve Sudokus
This post presents some of the results of a paper co-authored by Roman Kniazev and myself. Roman did most of the work.
This post is a companion to a gentle introduction to mechanistic interpretability, which explains the key concepts and tools used here, including transformers, hidden states, linear probes, direct logit attribution, and causal intervention. We recommend reading it first.
The technical paper is on Arxiv: https://arxiv.org/abs/2605.18847, the paper will be presented at the Mechanistic Interpretability workshop of ICML 2026.
Mechanistic interpretability studies how neural networks represent and compute information internally. A central question is whether models that learn to play games or solve puzzles develop genuine internal world models, that is, structured representations of the current state of the problem. A foundational result showed that a transformer trained only on Othello game transcripts spontaneously develops an internal cell-by-cell representation of board occupancy, even though it was never shown a board diagram during training. Linear probes (see the intro post) recover the full board state from the model’s hidden states with near-perfect accuracy.
Our paper asks: what happens when the task is not a board game with a natural cell-by-cell structure, but a constraint satisfaction problem? We study Sudoku, and the answer reveals something unexpected about how the geometry of a world model can reflect the algebraic structure of a problem.
Why Sudoku?
Sudoku is a natural testbed precisely because its difficulty is not spatial but structural. The 9×9 grid contains 81 cells, but the rules are defined over 27 overlapping substructures: 9 rows, 9 columns, and 9 boxes. Each substructure must contain every digit from 1 to 9 exactly once. Crucially, whether a digit can legally be placed in a given cell depends entirely on the contents of the three substructures that cell belongs to, namely its row, its column, and its box, not on the cell itself in isolation.
This creates a sharp question. In Othello, the most natural representation is cell-by-cell, and that is exactly what the model learns. In Sudoku, the constraints are organized by substructure. Which unit does the model choose when representing the current situation internally?
Following recent work, we trained a transformer with 8 layers and 8 attention heads on millions of Sudoku solving traces generated by a backtracking solver (a standard algorithm that tries placements one by one, reverting when it reaches a contradiction). Each trace is a sequence of steps (every digit placement is encoded as a discrete symbol called a token) including the backtracking steps. The model achieves 98.4% per-cell and 97.5% per-grid accuracy on held-out puzzles, meaning that it reliably solves Sudoku.
The representation is built around substructures, not cells
We probe the model’s internal states at the point just after reading the clues and before generating any placement. Three families of probes were trained and compared:
- Per-cell digit probes: “Which digit is in cell (r, c)?”
- Per-cell candidate probes: “For each digit, is it a valid candidate in cell (r, c)?” (i.e., has it not yet been used in the corresponding row, column, or box?)
- Per-substructure probes: “Is digit d present in substructure S?”
Per-cell digit probes plateau at around 80% accuracy and never do better. Per-substructure probes, by contrast, achieve perfect accuracy across all 243 (substructure, digit) combinations (27 substructures × 9 digits = 243) in the middle layers of the network.
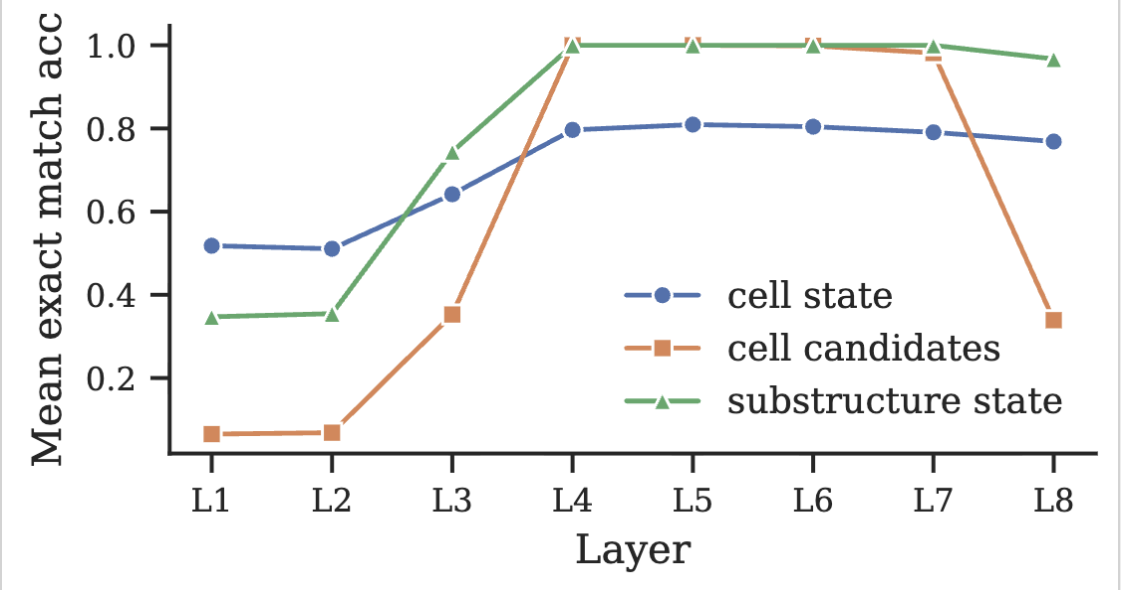
Mean exact-match accuracy of three families of linear probes over the model’s layers. Substructure probes (green) reach perfect accuracy in mid-layers, while per-cell digit probes (blue) plateau at 80%.
This first result was very surprising to us: the internal world model built by the Transformer is not in the form of a grid, as we visualise Sudokus, but by substructures, following the underlying algebraic structure of Sudokus!
We refer the reader to the paper for further details on this representation.
Mid-layer attention heads serve as constraint checkers
With the world model identified, the next question is which parts of the network build and use it. The answer points to the middle layers, and specifically to the attention mechanism, which is the part of the transformer that lets each position selectively read information from other positions in the sequence. Our goal here is to understand where each attention head focuses, and to quantify its impact on the final decision.
When the attention weights of mid-layer heads are projected back onto the 9×9 Sudoku grid, a clear pattern emerges: many heads concentrate their attention in a single box, others in a band (three horizontally adjacent boxes) or a stack (three vertically adjacent boxes). The figure below shows one example in detail: head L4H6 (layer 4, head 6), which specializes in columns 4–6.
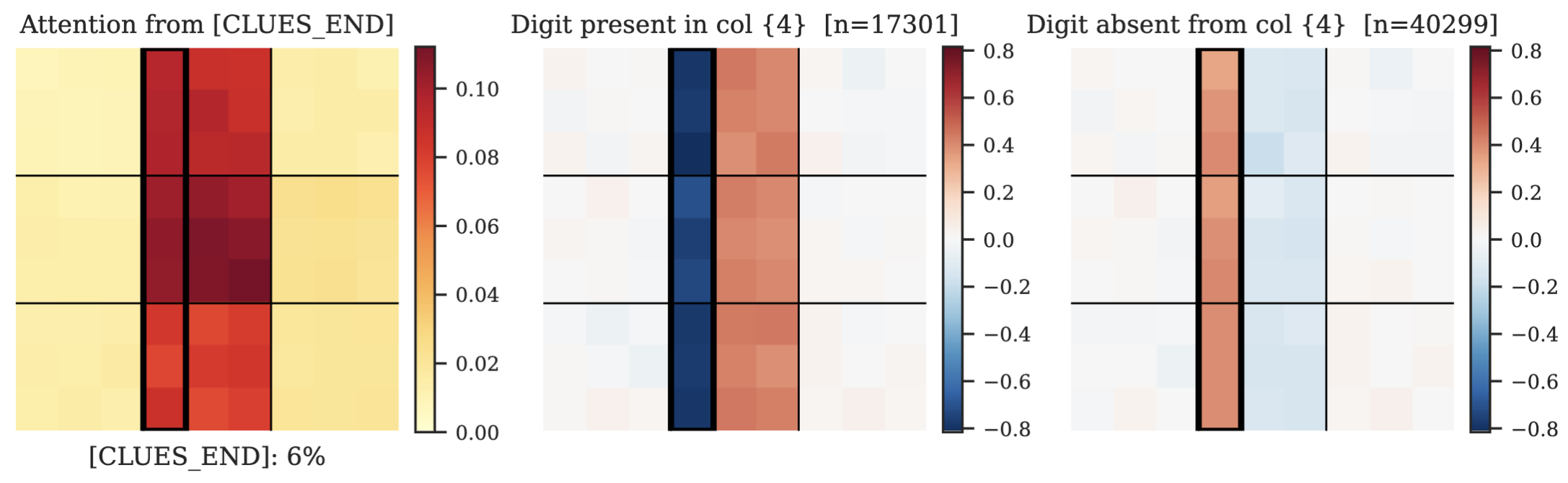
Left: The attention map of head L4H6, showing concentrated attention on tokens from the middle column stack. Middle and right: The direct contribution of this head to the model’s output scores, decomposed by whether a digit is already present (red) or absent (blue) in the target columns. The head suppresses digits already placed in its columns and promotes absent ones.
The mechanism these heads implement is symmetric and elegant. When a digit is already present in the attended substructure, the head suppresses the logit (the raw score the model assigns to each possible next placement) for placing that digit anywhere in the substructure. When a digit is absent, the head promotes it. This is exactly constraint elimination: the head is enforcing the rule that each digit appears exactly once per substructure.
This specialization is not perfect: some heads attend more broadly, but it is systematic, in the sense that for each of the box, band, and stack, there is at least one corresponding attention head. The figure below shows for each layer (the eight rows), the eight attention heads (the eight columns).
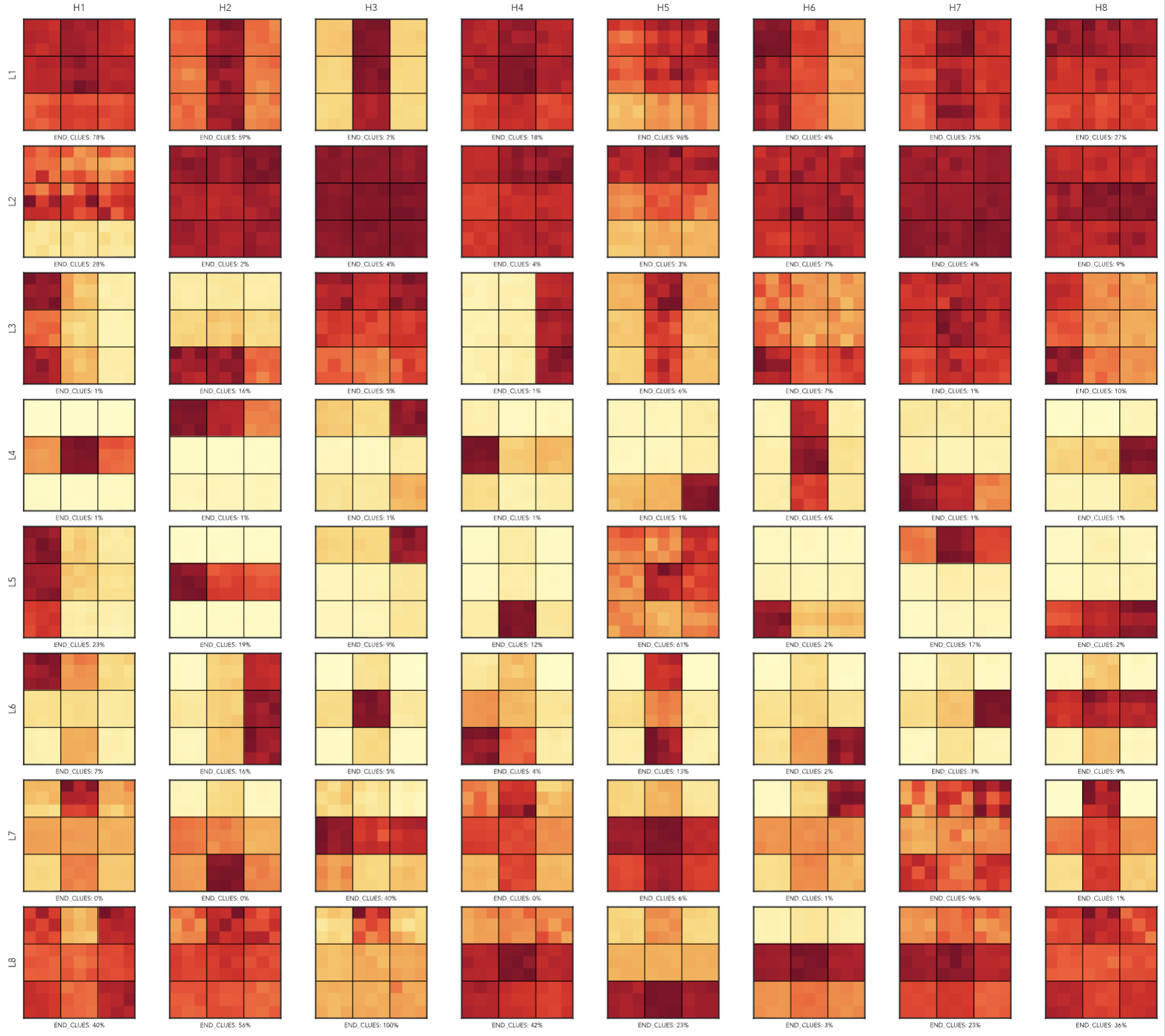
Last-layer neurons
Let us now study a concrete placement decision. Here we focus on the most common type of forced move: naked singles, where only one digit remains valid in a given cell.
Interestingly, before the final layer even acts, the model has already identified the right answer: for states with a naked single, the correct digit is ranked first among all nine candidates for that cell in 98.77% of cases, with a comfortable margin. The role of the last layer is therefore not to find the answer, but to amplify it into a confident prediction.
Looking at all neurons from the last layer, we find that 87 neurons act as dedicated naked-single detectors, each associated with a specific cell on the board. The activation pattern of a single such neuron is shown below.
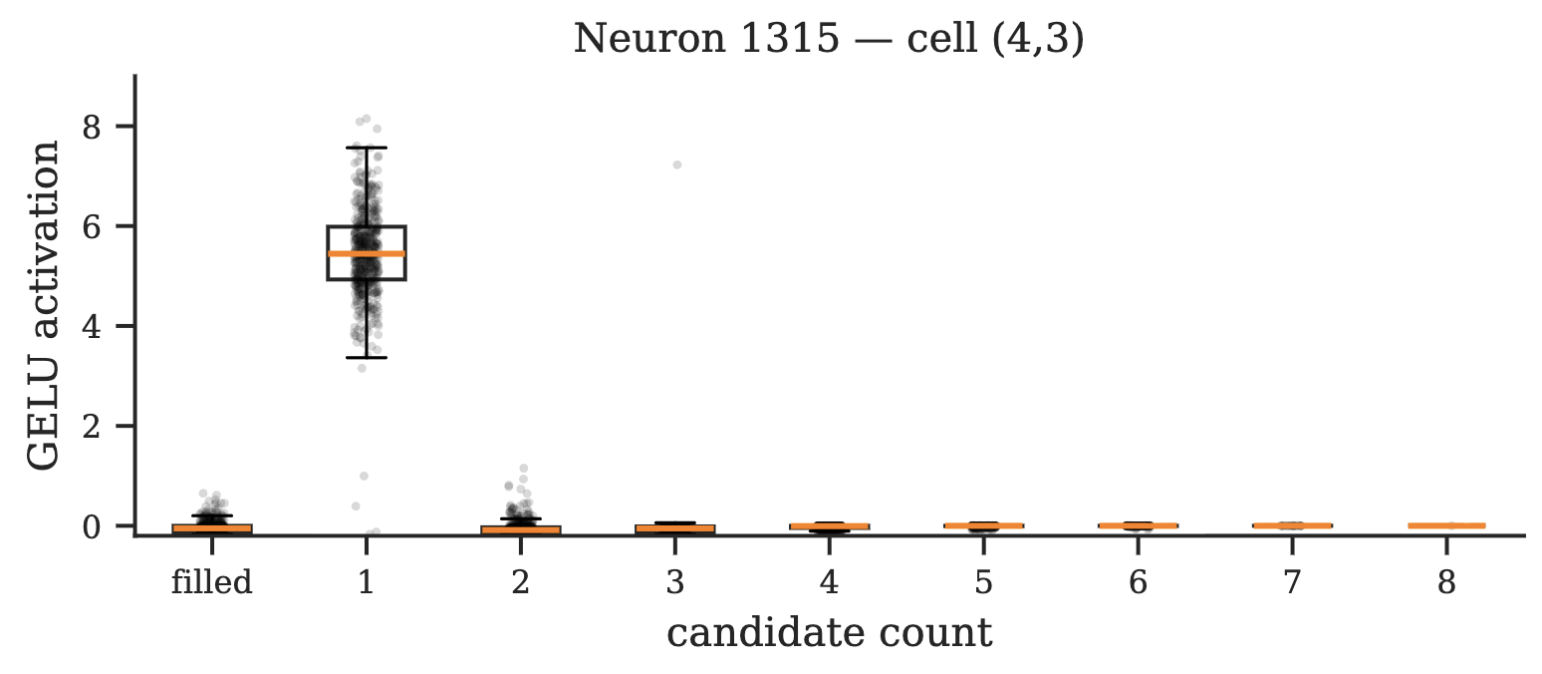
The distribution of activations for one naked-single detector neuron, grouped by the number of valid candidates remaining in its associated cell. The neuron fires strongly only when exactly one candidate remains (the naked-single condition) and is essentially silent otherwise.
These neurons are monosemantic (each does exactly one thing): each fires for one specific cell and only under the naked-single condition. When a naked-single neuron fires, it writes a large, digit-uniform boost to the logits of all nine placement tokens for its associated cell, raising all of them by about 3 logits on average, with negligible variance across the nine digits, and negligible effect on any other cell. Because the correct digit was already ranked first before this boost, the uniform amplification preserves the ranking, making the model commit confidently to that cell.
What this tells us about world models in AI
The picture that emerges from this analysis is unusually complete. A transformer trained to solve Sudoku develops a world model whose geometry is shaped not by the surface structure of the input (a 9×9 grid of cells) but by the algebraic structure of the problem’s constraints (27 substructures). This is a departure from what was found in Othello and chess, where the natural cell-by-cell decomposition of the board was linearly represented by the model.
The finding suggests that when a task has a non-trivial constraint algebra, neural networks may discover and internalize that algebra as part of learning to solve the task efficiently, without any explicit guidance. The specific substructures of Sudoku, which are what makes the puzzle hard to solve, are exactly what the model chooses to represent.
The mechanistic account is also unusually fine-grained: from the geometry of the world model, to the specialized attention heads that enforce the constraints, to the individual neurons in the final layer that detect forced moves. Each of these components does a specific, identifiable job, and removing any of them has measurable consequences. The result is a rare case in which a non-trivial neural network computation can be described from end to end.